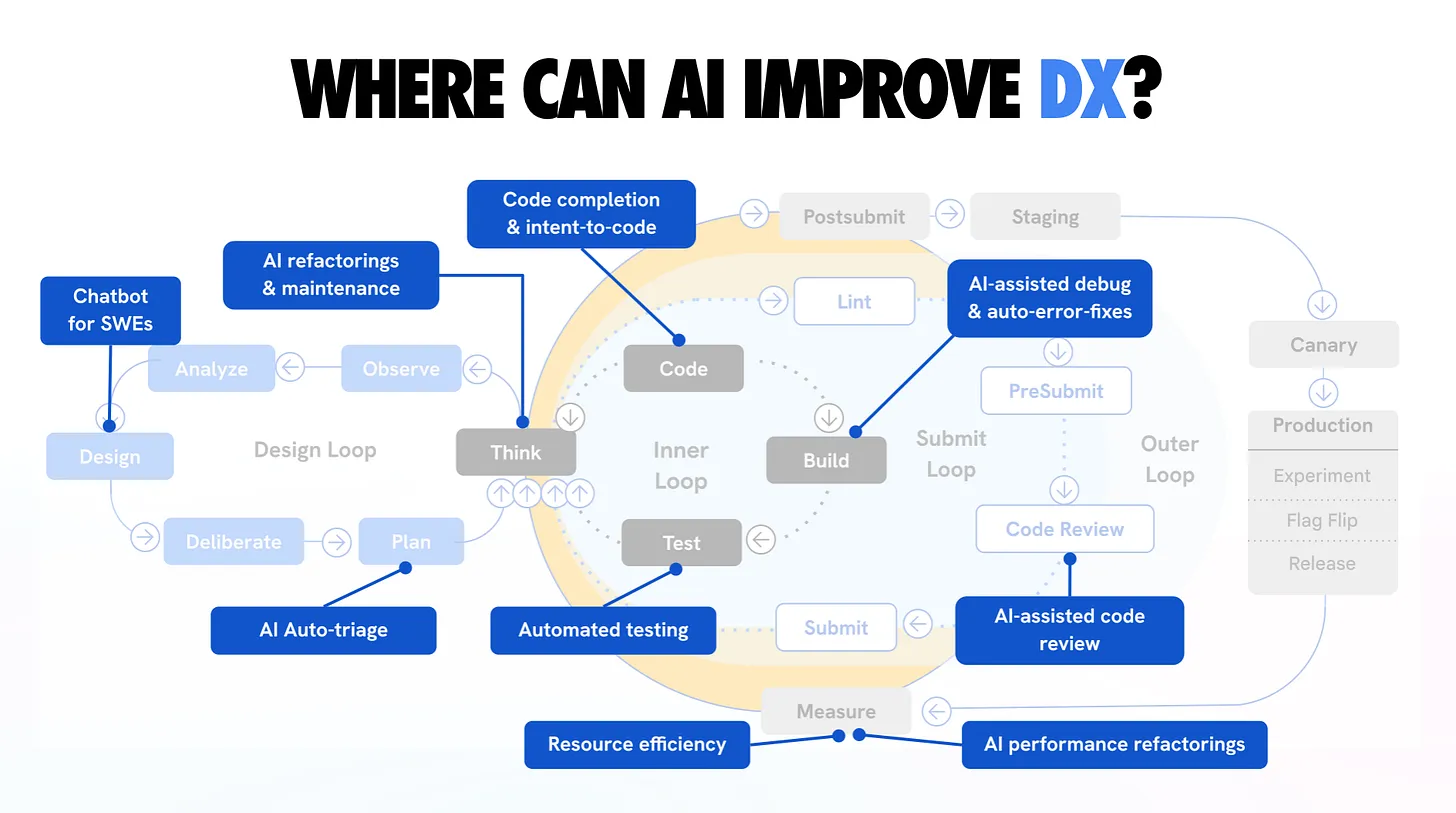
Use Test Driven Development with Claude Code to give your agent clear specs in the beginning and a clear signal in the end of a task. TDD, runtime logs, test traces, and focused debugging keep your specs on track while you scale.
I spent a couple of hours last year debugging a feature that Claude had marked as "done." The tests it wrote all passed. The code compiled. TypeScript had no complaints. But the function failed on three edge cases that only showed up in production logs. The problem was not purely the AI agent. The problem was that I let it define what "correct" meant.
METR's 2025 study put a number on this pattern. Experienced developers were 19% slower when using AI tools. The twist: they believed they were 20% faster. The Agile Manifesto's 25th anniversary workshop identified the fix: TDD produces dramatically better results from AI coding agents because it stops the agent from writing tests that verify broken behavior.
Google's 2025 DORA report frames the bigger picture. AI is an amplifier. It makes strong practices more effective and weak practices more dangerous. SonarSource's survey shows the gap: 96% of developers do not fully trust AI-generated code, yet only 48% always verify it before committing. That is a system running on hope instead of evidence.
TDD and AI: Quality in the DORA report
How TDD principles amplify AI success. Use automated testing and working in small batches to improve code quality. Download the DORA 2025 report.
Addy Osmani put it well:
The best results come when you apply classic software engineering discipline to your AI collaborations.
It turns out all our hard-earned practices - design before coding, write tests, use version control, maintain standards - not only still apply, but are even more important when an AI is writing half your code.
My LLM coding workflow going into 2026
AI coding assistants became game-changers this year, but harnessing them effectively takes skill and structure. Here
TDD is the practice that matters most here. You define what "correct" means first by creating specs or reviewing generated ones. Claude writes code to match that definition. If the tests pass, the code works. If they fail, Claude fixes them. No ambiguity, no "looks good to me" judgment call.
In this chapter, you build a testing framework around Claude Code that gives the agent clear specs in the beginning and a clear signal in the end of a task. You set up TDD workflows, process runtime logs and test traces so the agent knows what happened during each test run, and build a focused debug-test approach. When a test fails, the agent inspects screenshots, page snapshots, browser traces, and timeline steps to find the root cause: outdated test, broken code, or a change that broke something upstream.
Draft - In Progress. This chapter is currently being written. Full content coming soon.
6. Building a Feedback Loop
Give Claude Code eyes and ears so it can see your app and inspect its runtime, read logs, and verify across desktop and mobile channels.
8. The Complete SDLC Workflow
Follow a structured Research, Plan, Implement, Review, Ship workflow that consistently produces production-grade code.